Data-Enhanced Variational Monte Carlo for Rydberg Atom Arrays
Rydberg atom arrays are programmable quantum simulators capable of preparing interacting qubit systems in a variety of quantum states. Due to long experimental preparation times, obtaining projective measurement data can be relatively slow for large arrays, which poses a challenge for state reconstruction methods such as tomography. Today, novel groundstate wavefunction ansätze like recurrent neural networks (RNNs) can be efficiently trained not only from projective measurement data, but also through Hamiltonian-guided variational Monte Carlo (VMC). In this paper, we demonstrate how pretraining modern RNNs on even small amounts of data significantly reduces the convergence time for a subsequent variational optimization of the wavefunction. This suggests that essentially any amount of measurements obtained from a state prepared in an experimental quantum simulator could provide significant value for neural-network-based VMC strategies.
Paper: https://arxiv.org/abs/2203.04988
Paper: https://arxiv.org/abs/2203.04988
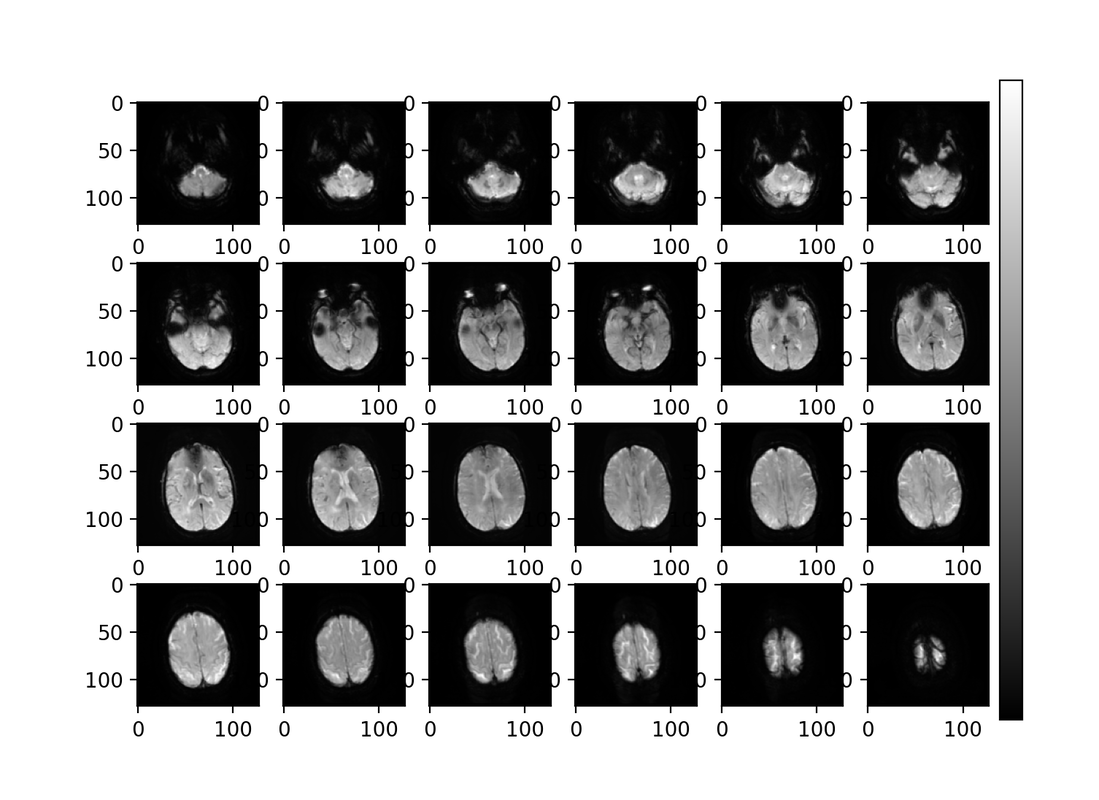
A deep learning approach to parameter mapping from perfusion MRI in ischemic stroke
We have pursued a deep learning approach using a U-Net architecture to magnetic resonance perfusion (MRP) imaging, also know as bolus-tracking MRI or perfusion weighted imaging to predict parametric perfusion maps (including time of maximum value of the residue function, Tmax). MRP is dynamically acquired using MRI by injecting a contrast bolus into the patient and repeatedly scanning the same image volume 30-40 times over ~3 minutes, generating a time series of 3D scans, or a 4D set of images. Typically, these scans are fed into complex mathematical models to generate parametric maps to assess the severity of stroke and select the patients to undergo therapy.
However, this mathematical modelling software, RAPID, is very expensive and many hospitals cannot afford it. Therefore, we generate useful parametric maps directly from the MRP without utilizing RAPID, which has the potential to save lives by enabling more hospitals to quickly predict key parametric maps in order to better treat and stratify ischemic stroke patients. An additional benefit of using DL for generating parametric maps (in this case, we choose to predict Tmax maps) is to avoid the need for arterial sampling in patients during scanning (which is necessary for the RAPID approach). Tmax is chosen since it has been demonstrated to have the most clinical utility out of the parameters computed by RAPID and is especially useful in determining which stroke patients are good candidates for thrombolysis, a potentially life-saving treatment with many absolute contraindications, where treatment must commence within hours of the stroke.
However, this mathematical modelling software, RAPID, is very expensive and many hospitals cannot afford it. Therefore, we generate useful parametric maps directly from the MRP without utilizing RAPID, which has the potential to save lives by enabling more hospitals to quickly predict key parametric maps in order to better treat and stratify ischemic stroke patients. An additional benefit of using DL for generating parametric maps (in this case, we choose to predict Tmax maps) is to avoid the need for arterial sampling in patients during scanning (which is necessary for the RAPID approach). Tmax is chosen since it has been demonstrated to have the most clinical utility out of the parameters computed by RAPID and is especially useful in determining which stroke patients are good candidates for thrombolysis, a potentially life-saving treatment with many absolute contraindications, where treatment must commence within hours of the stroke.
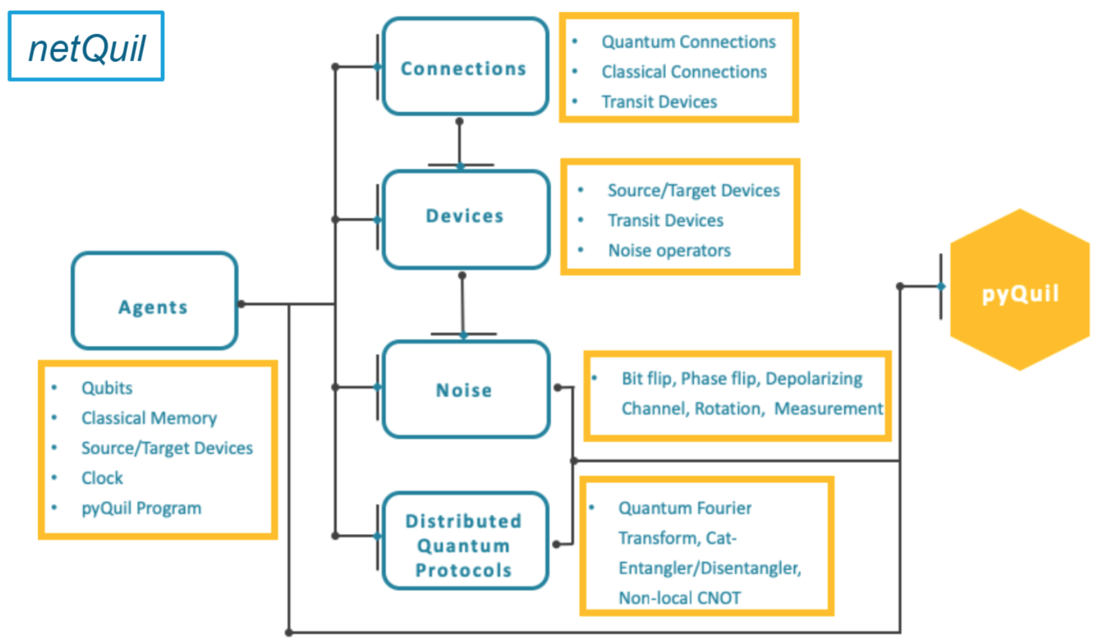
netQuil: A quantum playground for distributed quantum computing simulations
GitHub
NetQuil is an open-source Python framework designed specifically for simulating quantum networks and distributed quantum protocol. Built on the already extensive quantum computing framework pyQuil, by Rigetti Computing, netQuil is perfect for extending your current quantum computing experiments and testing ideas in quantum network topology and distributed quantum protocol.
Submitted to March Meeting 2020
Talk:
NetQuil is an open-source Python framework designed specifically for simulating quantum networks and distributed quantum protocol. Built on the already extensive quantum computing framework pyQuil, by Rigetti Computing, netQuil is perfect for extending your current quantum computing experiments and testing ideas in quantum network topology and distributed quantum protocol.
Submitted to March Meeting 2020
Talk:
| finalmarchmeeting.pdf |
A QAOA solution to the traveling salesman problem using pyQuil
GitHub
The traveling salesman problem (TSP) is a famous NP-complete optimization task with classical algorithms relying on either enumerating every possible path and checking its value or solving relaxed problems and then polishing for feasible solutions, such as branch-and bound algorithm, with often worst case runtime O(n!). We create a Quantum Approximate Optimization Algorithm (QAOA) to define a Hamiltonian that enforces the constraints of the problem and can find the ground state of the Hamiltonian, which can be done efficiently in a quantum system.
The traveling salesman problem (TSP) is a famous NP-complete optimization task with classical algorithms relying on either enumerating every possible path and checking its value or solving relaxed problems and then polishing for feasible solutions, such as branch-and bound algorithm, with often worst case runtime O(n!). We create a Quantum Approximate Optimization Algorithm (QAOA) to define a Hamiltonian that enforces the constraints of the problem and can find the ground state of the Hamiltonian, which can be done efficiently in a quantum system.

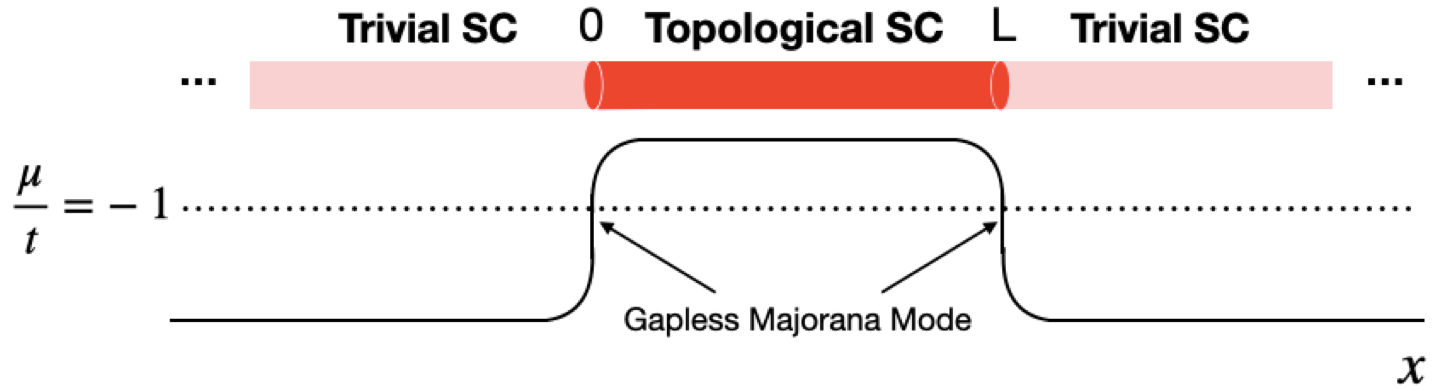
Topological Quantum Phases Through Majorana Wires Stabilized by Many-Body Localization
Many-body Quantum Dynamics Paper
Quantum computing has been vigorously pursued because of its promise of a number of revolutionary applications ranging from cryptography (e.g., Shor's exponential speedup of prime factorization) to solutions of many challenging problems of quantum chemistry and material science. Popular platform candidates include photon time-bin encoded qubits, superconducting qubits, ion trap qubits, among others. However, the emergence of topological qubits theoretically provides a foundation for more robust qubits that store information non-locally and are therefore robust to deleterious effects of local noise. In this paper, we investigate the theory behind Majorana fermions, as appearing at the ends of gated wires of spinless p-wave superconductors, and discuss their utilization for topological quantum computing. We also explore the possibility of expanding the range of stability of the corresponding Majorana phases in the presence of quenched disorder, viewing it through its Jordan-Wigner mapping onto the random transverse field Ising model.
Quantum computing has been vigorously pursued because of its promise of a number of revolutionary applications ranging from cryptography (e.g., Shor's exponential speedup of prime factorization) to solutions of many challenging problems of quantum chemistry and material science. Popular platform candidates include photon time-bin encoded qubits, superconducting qubits, ion trap qubits, among others. However, the emergence of topological qubits theoretically provides a foundation for more robust qubits that store information non-locally and are therefore robust to deleterious effects of local noise. In this paper, we investigate the theory behind Majorana fermions, as appearing at the ends of gated wires of spinless p-wave superconductors, and discuss their utilization for topological quantum computing. We also explore the possibility of expanding the range of stability of the corresponding Majorana phases in the presence of quenched disorder, viewing it through its Jordan-Wigner mapping onto the random transverse field Ising model.
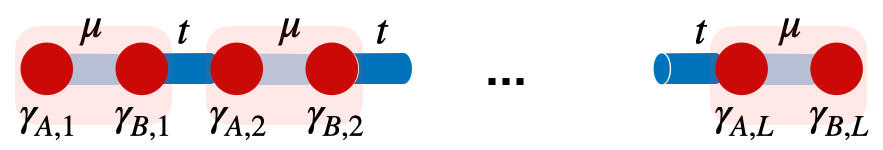
Debiasing Recidivism Risk Scores using GANs
GitHub
High imprisonment rates in the US have led courts to start using quantitative risk assessment software when making decisions about sentencing and releasing inmates. However, with particular fairness metrics, research has shown a bias against black inmates. To counteract this racial bias, we present a generative adversarial network (GAN) that predicts recidivism scores without imbuing the personal bias and prejudice that inevitably are present with a human decision maker, or even current risk assessment software.
High imprisonment rates in the US have led courts to start using quantitative risk assessment software when making decisions about sentencing and releasing inmates. However, with particular fairness metrics, research has shown a bias against black inmates. To counteract this racial bias, we present a generative adversarial network (GAN) that predicts recidivism scores without imbuing the personal bias and prejudice that inevitably are present with a human decision maker, or even current risk assessment software.

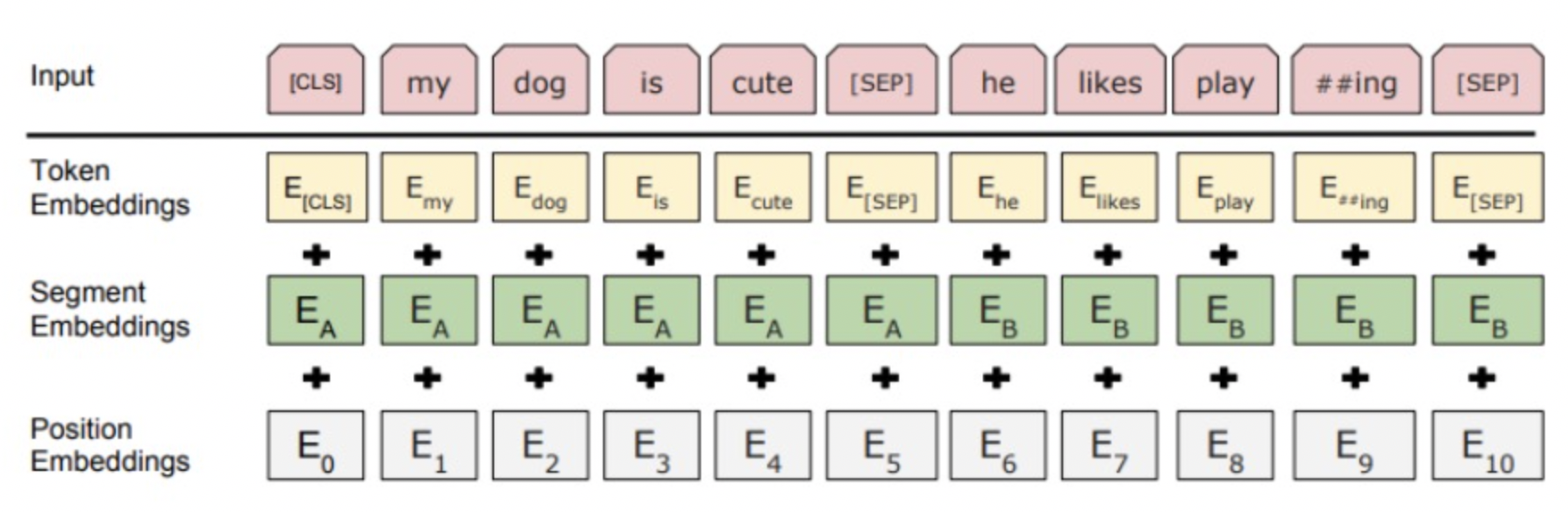
Question Answering: Dependency Parsing with BERT and Using an Ensemble
GitHub
Bidirectional Encoder Representations from Transformers (BERT) implements bidirectional pre-training for language representation using masked language models from Cloze tasks and next sentence prediction (NSP). Previous frontier pre-trained language representations used unidirectional language models for pre-training. This includes models focused on attention, namely transformers, where multiple attention heads attend to pieces of the input, including Embeddings from Language Models (ELMo) and Generative Pre-trained Transformer (OpenAI GPT). Note, that BERT’s bidirectional language model for pre-training differs from simply concatenating independent unidirectional language models such as in ELMo, and instead jointly conditions on tokens from the both directions in each layer. This allows for a less expensive model, intuitive models (since conditioning on the answer does not make sense), and bidirectional context in each layer.
We aim to improve performance of question and answering for SQuAD 2.0 by using an ensemble of multiple state-of-the-art models. Our initial model implements a voting scheme with four fine-tuned SQuAD models "voting" for the correct answer, and outputting the majority answer. Also, we train a neural layer that takes in the output of each model as well as the question, in order to learn which model is best for each type of question. We attempt to implement dependency parsing as a fine-tuning task such that we have a better pre-trained model before fine-tuning for question and answering.
Bidirectional Encoder Representations from Transformers (BERT) implements bidirectional pre-training for language representation using masked language models from Cloze tasks and next sentence prediction (NSP). Previous frontier pre-trained language representations used unidirectional language models for pre-training. This includes models focused on attention, namely transformers, where multiple attention heads attend to pieces of the input, including Embeddings from Language Models (ELMo) and Generative Pre-trained Transformer (OpenAI GPT). Note, that BERT’s bidirectional language model for pre-training differs from simply concatenating independent unidirectional language models such as in ELMo, and instead jointly conditions on tokens from the both directions in each layer. This allows for a less expensive model, intuitive models (since conditioning on the answer does not make sense), and bidirectional context in each layer.
We aim to improve performance of question and answering for SQuAD 2.0 by using an ensemble of multiple state-of-the-art models. Our initial model implements a voting scheme with four fine-tuned SQuAD models "voting" for the correct answer, and outputting the majority answer. Also, we train a neural layer that takes in the output of each model as well as the question, in order to learn which model is best for each type of question. We attempt to implement dependency parsing as a fine-tuning task such that we have a better pre-trained model before fine-tuning for question and answering.
Modeling Epidemics: COVID-19 & Moving Forward
Epidemic modeling has been deeply explored in order to predict and take precautions for the possibility of an outbreak and handling an outbreak, from compartmental models, randomized models, and graph models among others. Motivated by the COVID-19 pandemic, we investigate four compartmental models and their dynamics with added complexities including birth and death rates, spatial graph models, and second wave dynamics. Mathematically we find stable equilibrium points and visually demonstrate the dynamics of the spread of the disease through 2D spatial models of the diseases growth over time for different parameters. We find that, generally, there is a phase transition between a growing pandemic state and an absorbing non-pandemic state at the critical point where the reproductive number is 1. We hope that these simple models elucidate epidemic terminology, assist understanding of the emergence of the possibility of a second wave of infections, and reveal the complexities of such epidemic models.
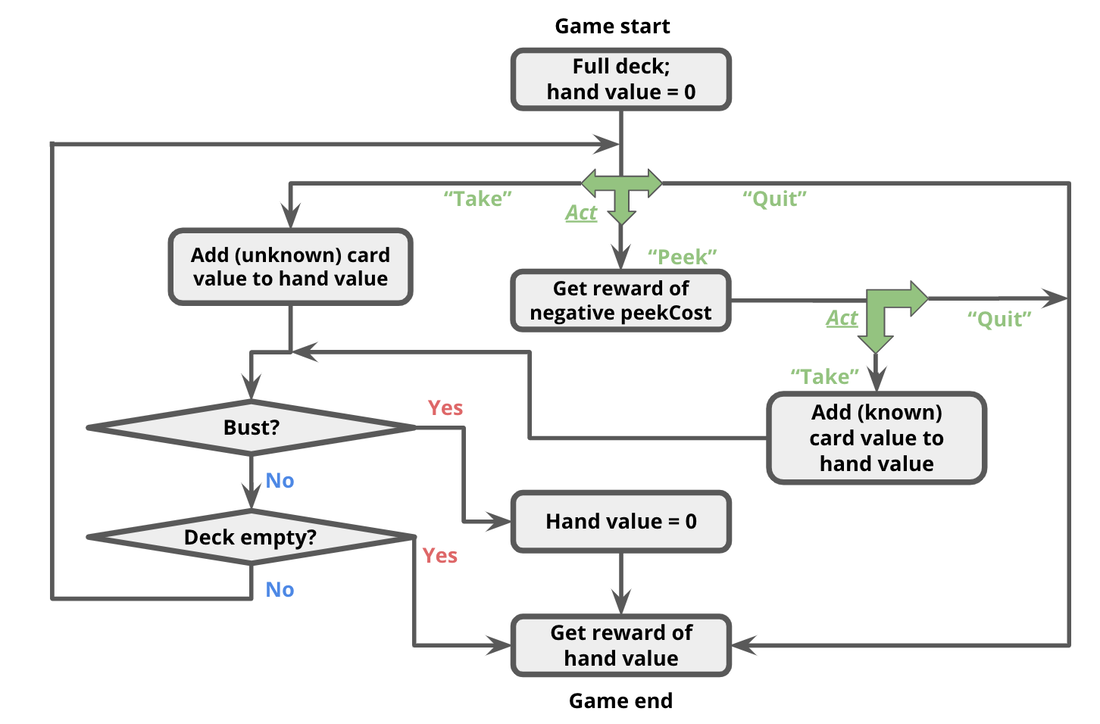
Beating the House in Blackjack using Reinforcement Learning
Modeled the game of Blackjack as a Markov Decision Process (MDP) and then as Partially Observed MDP (POMDP). Used Q-learning with epsilon greedy and softmax exploration to learn the optimal policy of the game of Blackjack under different variants of the game, such as multiple players, different betting schemes, fixed number of decks, peeking Blackjack and scheduled reshuffles.

|
|
